Discrete Vision-Language-Action (VLA) models typically formulate action generation as
next-token prediction over discretized action spaces, conditioning each token
autoregressively on prior context. While effective, this paradigm incurs high inference
latency and largely ignores the temporal structure inherent in action trajectories.
Recent efforts introduce parallel decoding to improve efficiency, enabling faster
inference, but lack explicit mechanisms for modeling token dependencies.
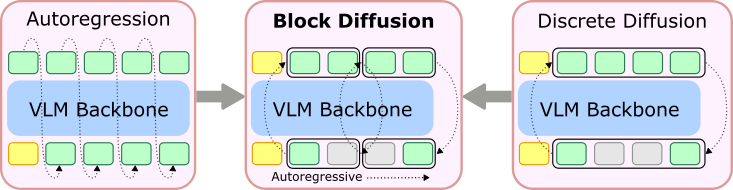
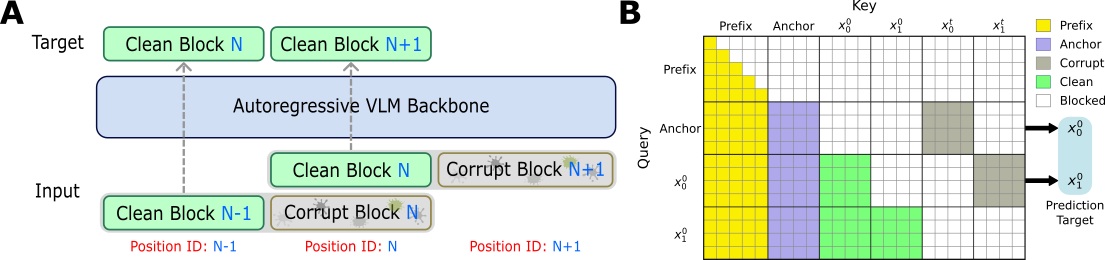
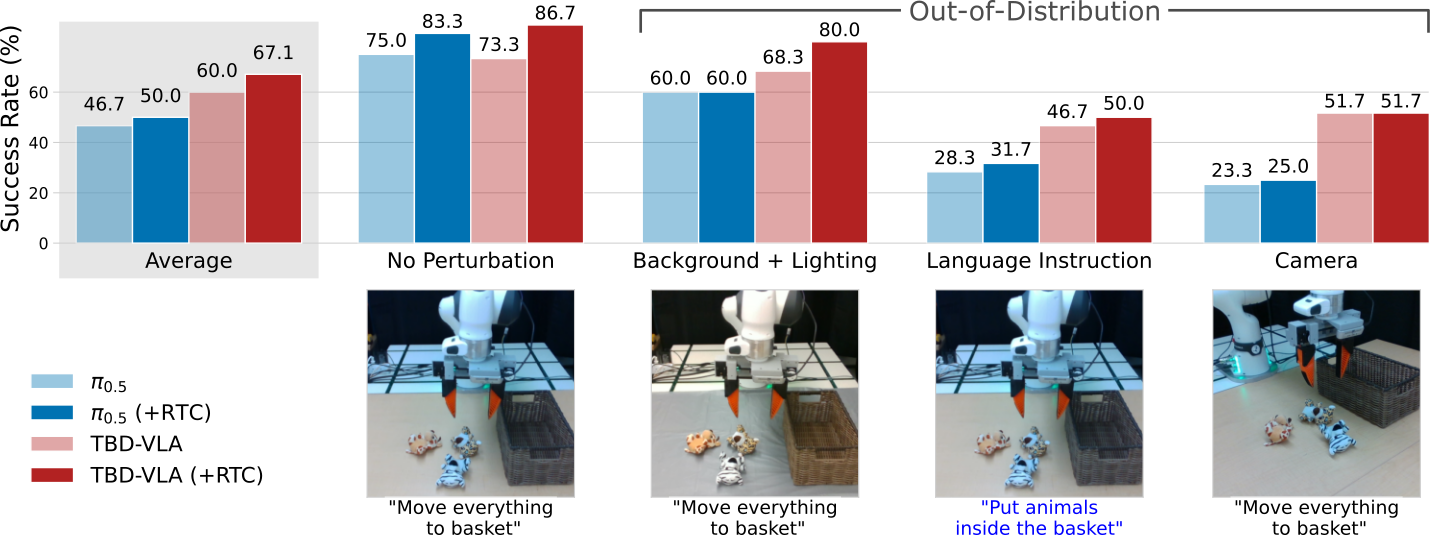
We introduce TBD-VLA, a discrete token-based VLA framework that incorporates
block diffusion to enable temporal action generation. We partition action
sequences into temporal blocks and perform masked discrete diffusion within each block,
while maintaining autoregressive generation across blocks. This design unifies temporal
autoregression and parallel action decoding, achieving both strong temporal coherence and
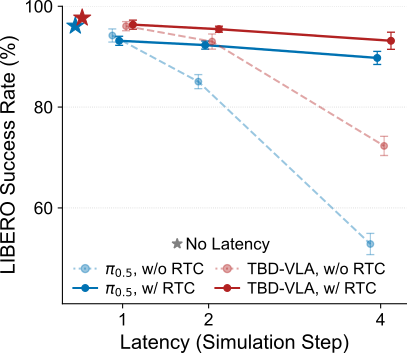
improved inference speed. In addition, the explicit temporal modeling enables asynchronous
execution of action chunks (e.g., Real-Time Chunking) via temporal in-painting. TBD-VLA
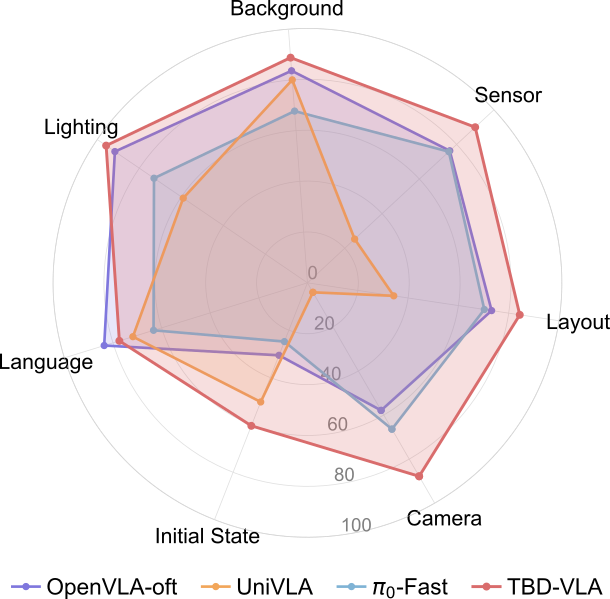
significantly outperforms prior VLA approaches in both simulation and real-world
manipulation tasks, offering a scalable path toward fast, temporally aware, discrete VLA
models.